





Kun Facebookissa ja Instagramissa alkoi kiertää haaste, jossa ihmiset postaavat rinnakkain ensimmäisen ja viimeisen kuvan itsestään, en halunnut osallistua. En niinkään sen takia, että kokisin haasteessa jotain epäilyttävää, vaan koska oma Facebook-profiilikuvani oli tylsä silloin ja on tylsä nyt.
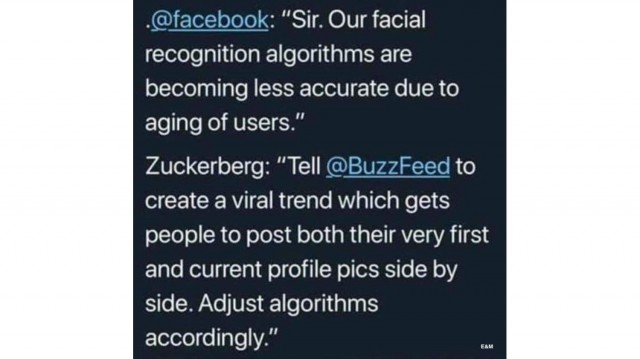
Sen sijaan törmäsin meemiin, jossa irvaillaan Facebookin ja Buzzfeedin järjestäneen haasteen parantaakseen kasvojen tunnitusalgoritmin kykyä tunnistaa ihmisten ikääntyminen ja jaoin sen.
Haastetta on ohjeistettu eri tavoin, mutta yleensä ohjeet neuvovat lisäämään ensimmäisen ja viimeisimmän profiilikuvan tai kuvat, joiden ottamisen välillä on 10 vuotta.
Varmaa tietoa haasteen alkuperästä minulla ei ollut, mutta meemi sai tajuamaan, millaisiin tarkoituksiin haastetta on mahdollista käyttää.
Samoilla linjoilla oli Wiredin mielipidesivuille kirjoittanut tietokirjailija Kate O’Neill. O’Neill ei myöskään osallistunut haasteeseen, vaan kirjoitti sen sijaan seuraavan twiitin:
Me 10 years ago: probably would have played along with the profile picture aging meme going around on Facebook and Instagram
— Kate O'Neill (@kateo) January 12, 2019
Me now: ponders how all this data could be mined to train facial recognition algorithms on age progression and age recognition
O’Neill otti siis haasteeseen osaa kertomalla, miten hänen suhtautumisensa vastaaviin haasteisiin on muuttunut kymmenessä vuodessa. Hänen ajatuksensa keräsi huomiota Twitterissä, mutta monet eivät sitä purematta nielleet.
Yleisin vasta-argumentti ajatukselle, että “10 vuoden haaste” olisi tarkoitettu keräämään kasvojen tunnistusdataa ikääntymisestä, oli se, että kuvat ovat jo valmiiksi julkisia ja niistä löytyy aikakoodit, joten data on mahdollista louhia esiin ilman käyttäjien ystävällistä avustustakin.
Tähän O’Neill vastaa selittämällä, millainen hyöty on siitä, että käyttäjä itse valitsee kuvansa ja asettaa ne rinnakkain. Louhimalla kaikkia vanhoja kuvia läpi dataan päätyy kaikenlaista turhaa, sillä ihmiset eivät ole välttämättä postanneet kuviaan kronologisesti tai ne eivät välttämättä esitä käyttäjää.
“Toisin sanoen siitä olisi apua, jos tarjolla olisi puhdas, yksinkertainen ja selkeästi nimetty datasetti ennen ja jälkeen kuvia”, O’Neill kirjoittaa.
Villisti kiertävä haaste on siis luonut ison ja laadukkaan kasan dataa, jota olisi mahdollista käyttää kasvojen tunnistusalgoritmin opettamiseen.

Turhaan foliohattuiluun ei ole syytä, mutta samaan aikaan Facebookin viimeaikaiset toimet eivät herätä luottamusta tavasta, jolla palvelu kohtelee ihmisten dataa. Yhdysvaltain vaaleihin vaikuttanut Cambridge Analytica käytti nimenomaan erilaisia sosiaalisia pelejä, meemejä ja haasteita kerätessään valtavan datamääränsä.
Kuten O’Neill toteaa, kasvojentunnistuksen kehittyminen ei ole välttämättä vaarallista ja monella tapaa väistämätöntä. Kyse on kuitenkin isommasta kysymyksestä eli siitä, millä tavoin internetiin jättämäämme dataa voidaan käyttää ja kuinka tietoisia siitä käyttäjinä olemme.